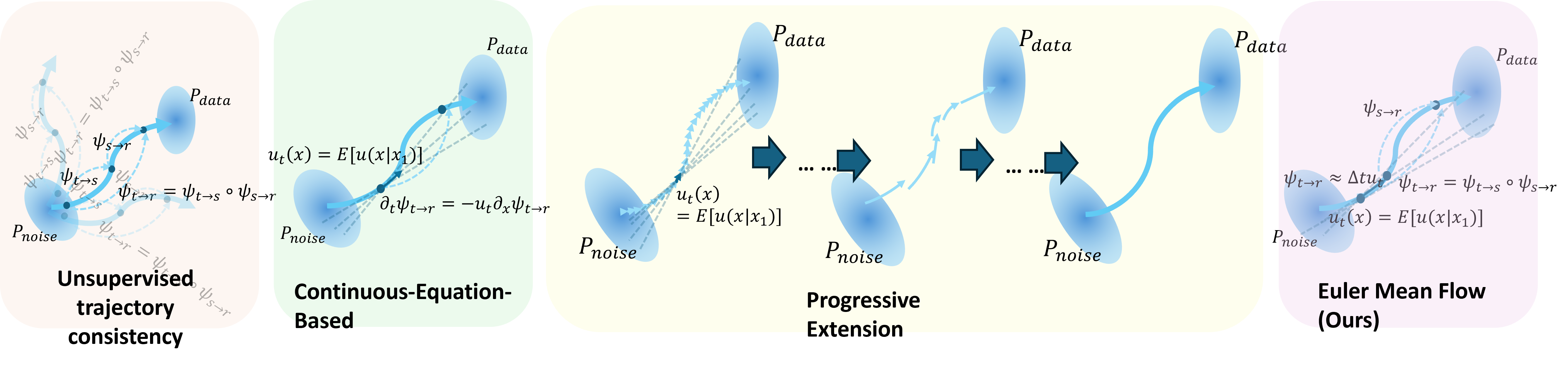
Trajectory consistency is indirect
Trajectory consistency is a fundamental property of flow maps: composing shorter maps should agree with the corresponding long map.
\[
\mathcal L^{TC} =
\mathbb E\left[
\left\|
\psi^\theta_{t\to r}(x_t) -
\psi^\theta_{s\to r}\!\left(
\psi^\theta_{t\to s}(x_t)\right)
\right\|^2
\right].
\]
However, this loss only enforces consistency between model outputs. It does not directly ensure that long maps match the target distribution.